채수원 님의 TDD(Test Driven Development) 개발 실천법과 도구는 소프트웨어 개발 방법론 중 하나인 TDD를 구체적으로 실천하는 방법과 그 과정에서 사용되는 도구들에 대한 내용을 다룬 책이다. TDD 대한 이해를 높이고 실제 개발에 적용하는 방법을 설명한다. TDD(Test Driven Development)는 소프트웨어 개발 방법론 중 하나로, 테스트 케이스를 먼저 작성하고 이를 통과하는 코드를 작성하는 것을 중심으로 개발하는 방법
책에서는 TDD의 개념과 원칙을 소개하며 테스트 케이스(TC) 작성, 코드 작성, 리팩토링 등의 단계별로 구체적인 예시를 보여준다. 특히 TC 작성과 이를 통한 코드 작성의 중요성에 대해 강조하며 TDD의 장점과 효과를 다양한 관점으로 보여준다. 책에서는 TDD를 실천하는 데 필요한 기본적인 원칙과 방법론을 설명하면서, 이를 구현하는 과정에서 발생하는 이슈와 해결 방법 등에 대해서도 다룬다. TDD를 적용하는 데에 있어 좋은 습관과 나쁜 습관을 비교하며 TDD를 대하는 개발자의 태도화 실천할 것들을 제시한다.
TDD를 실천하는 과정은 다음과 같다.
테스트 케이스 작성 : 먼저 개발하려는 기능에 대한 테스트 케이스를 작성. 작성한 테스트 케이스는 해당 기능이 정확히 동작하는지 검증하기 위한 목적으로 작성한다.
테스트 실행 : 작성한 테스트 케이스를 실행하여 해당 기능이 제대로 구현되어 있는지 확인. 이때, 테스트 케이스가 실패하면 해당 기능의 구현이 제대로 이루어지지 않았다는 것을 의미.
코드 작성 : 테스트 케이스를 통과하기 위한 코드를 작성. 이때, 테스트 케이스가 통과하도록 코드를 작성하는 것이 중요함.
코드 리팩토링 : 작성한 코드를 리팩토링하여 더 효율적이고 가독성이 좋은 코드로 개선.
이런 과정을 반복하며 개발하는 것이 TDD의 핵심이다. 이 과정에서 개발자는 작성한 코드가 정상적으로 동작하는지 항상 확인할 수 있으며, 버그를 빠르게 발견하고 수정할 수 있다고. 또한, 작성한 코드를 리팩토링하면서 코드의 유지 보수성과 확장성을 높일 수 있다고 한다.
TDD를 실천하는 개발자들은 코드 품질과 안정성을 높일 수 있으며, 개발 프로세스를 보다 효율적으로 관리할 수 있다고 한다. 또한, TDD는 기능 구현 외에도 코드의 문서화와 같은 부가적인 기능을 제공할 수 있어, 소프트웨어 개발의 생산성을 높일 수 있다고 한다.
TDD를 처음 접하는 초심자에게 유용한 정보이지만 초판 이후 어른들의 사정으로 재판이 나오지 않았고, 옛날 기술이나 라이브러리에 대한 설명이 많다. TDD를 업무에서 실 사용해보지 않은 내 입장에서는 일단 겪어봐야 할 것 같다. SW 품질을 높이는데 철학이 없는 조직에서는 TDD를 적용하기가 쉽지 않아서, 어쩌면 뜬구름 잡는 소리로 보이는 것도 있을 것 같다. 그치만 나는 내 일을 하면서 SW 품질을 높이는 데 많은 목마름이 있기에 꼭 TDD를 경험해 봐야 할 것 같다. 일단 나는 사이드 프로젝트에서 TDD를 사용해야겠다.
오라클 DB의 예상 실행 계획만으로는 성능 개선에 어려움을 겪을 때가 있음. 실제 실행 계획을 보고 문제점을 진단할 수 있어야 함. gather_plan_statistics 힌트는 Oracle SQL에서 SQL 문의 실제 실행 통계를 수집할 수 있는 기능. 이 힌드를 사용하면 Oracle DB는 SQL 실행 계획의 각 단계에서 처리된 행 수, 사용된 메모리 양 및 각 단계에서 사용된 시간과 같은 자세한 통계를 수집함.
GATHER_PLAN_STATISTICS으로 수집 가능한 정보
각 단계에서 수행되는 레코드 수, 시간 및 I/O 통계
각 단계에서 사용된 실행 계획
SQL 문의 최적 실행 계획과 실제 실행 계획의 차이를 나타내는 비교 정보
GATHER PLAN STATISTICS 사용 법
SQL 문에 다음과 같이 간단히 추가하면 됨.
SELECT /*+ gather_plan_statistics */ column1, column2, ...
FROM TABLE
WHERE ...
DBMS_XPLAN.DISPLAY_CURSOR
성능 문제를 진단하고 SQL 문을 최적화하는데 유용함. /*+ gather_plan_statistics */ SQL을 실행한 후, DBMS_XPLAN.DISPLAY_CURSOR 함수를 사용하여 실행 계획과 관련된 통계를 볼 수 있음. DISPLAY_CURSOR 함수는 실행 계획과 통계의 자세한 보고서를 반환하므로 SQL 문의 성능을 분석하고 최적화할 부분을 식별하는 데 사용할 수 있음.
최적 실행 계획과 실제 실행 계획의 비교
각 실행 계획 단계에서 수행된 레코드 수, 시간 및 I/O 통계
각 실행 계획 단계에서 사용된 인덱스 및 조인 방법 등의 정보
PREDICATE INFORMATION 섹션에서는 WHERE절과 JOIN 조건에 대한 추가 정보도 제공함
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT => 'ALLSTATS LAST'));
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(null, null, 'ALLSTATS LAST'));
DISPLAY_CURSOR 매개 변수
SQL_ID : 실행 계획과 통계를 검색하려는 SQL 문의 SQL_ID
CURSOR_CHILD_NO : [OPTIONAL] 실행 계획을 검색하려는 SQL 문의 부모 커서 번호, 생략시 첫 번째 커서(부모 커서)가 대상이 됨
FORMAT : 출력 형식 지원, 여러가지 출력 옵션이 있음. FORMAT=>'ALLSTATS LAST'를 사용하면 모든 실행계획 정보와 통계를 검색함.
SQL_ID 찾기
SQL_ID를 가져오기 위해 현재 DB에 접속한 SESSION에서 실행한 SQL 문의 히스토리를 검색하여 정보를 가져옴.
--------------------------------------------------------------------------------
-- SQL_ID, CHILD_NUMBER 추출
--------------------------------------------------------------------------------
SELECT
SA.SQL_ID,
S.CHILD_NUMBER,
SA.SQL_TEXT,
SA.MODULE,
SA.LAST_LOAD_TIME,
SA.LAST_ACTIVE_TIME,
SA.PLAN_HASH_VALUE,
SA.OPTIMIZER_COST,
SA.FETCHES,
SA.EXECUTIONS,
SA.cpu_time,
SA.ELAPSED_TIME,
S.DISK_READS,
S.PARSE_CALLS,
S.BUFFER_GETS,
S.ROWS_PROCESSED,
SA.PARSING_USER_ID,
SA.PARSING_SCHEMA_ID,
SA.PARSING_SCHEMA_NAME
FROM V$SQLAREA SA
/* V$SQLAREA : 공유 SQL 영역 */
INNER JOIN V$SESSION SS
/* V$SESSION : 현재 세션에 대한 정보 */
ON SA.PARSING_USER_ID = SS.USER#
AND SA.PARSING_SCHEMA_ID = SS.SCHEMA#
INNER JOIN V$SQL S
/* V$SQL : 공유 SQL 영역 내 쿼리에 대한 정보 */
ON SA.SQL_ID = S.SQL_ID
WHERE SS.AUDSID = USERENV('SESSIONID')
/* 현재 세션과 같은 SESSION ID */
AND SS.SID = USERENV('SID')
/* 특정 스키마 */
AND SA.PARSING_SCHEMA_NAME = 'IDLOOK'
/* 약 15분 이내에 실행한 쿼리만 조회 */
AND SA.LAST_ACTIVE_TIME >= SYSDATE - 0.01
/* 제외 */
AND sa.PARSING_SCHEMA_NAME NOT IN ('SYS', 'SYSTEM')
AND sa.SQL_TEXT NOT LIKE '%DBMS%'
AND sa.SQL_TEXT NOT LIKE '%V$%'
/* 실행 모듈이 운영 또는 타 시스템에서 실행한 쿼리라면 제외 */
AND SA.MODULE NOT IN ('DBMS_SCHEDULER', 'JDBC Thin Client', 'w3wp.exe')
/* 특정 문자열 제외*/
AND NOT REGEXP_LIKE(UPPER(SA.SQL_TEXT), 'V\$SQL|PLAN_TABLE|DBMS_XPLAN|EXTRACTVALUE\(|XMLSEQUENCE\(|CURRENT_SCHEMA|DBA_|DBMS_UTILITY|CONSTRAINT')
ORDER BY SA.LAST_ACTIVE_TIME DESC, SA.SQL_ID, S.CHILD_NUMBER
;
권한 문제
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'ALLSTATS LAST')); 쿼리 실행 시 권한 부족한 경우 DBA 계정으로 로그인하여 권한 부여 작업을 수행하거나 DBA 권한이 있는 사용자에게 권한을 부여해야 함. DBMS_XPLAN.DISPLAY_CURSOR 함수를 사용하려면 V$SESSION, V$SQL_SESSION, V$SQL(OPTIONAL), V$SQL_PLAN_STATISTICS_ALL 권한이 필요. (해당 권한이 없는 경우 ORA-01031: insufficient privileges 오류가 발생)
작동 조건
PLAN_STATISTICS 정보는 다음 조건 중 하나를 만족해야 함.
STATISTICS_LEVEL PARAMETER 값을 ALL로 변경 한 경우 ALTER SESSION SET STATISTICS_LEVEL = ALL;
_ROWSOURCE_EXECUTION_STATISTICS PARAMETER 값을 TRUE로 변경한 경우
GATHER_PLAN_STATISTICS HINT를 사용
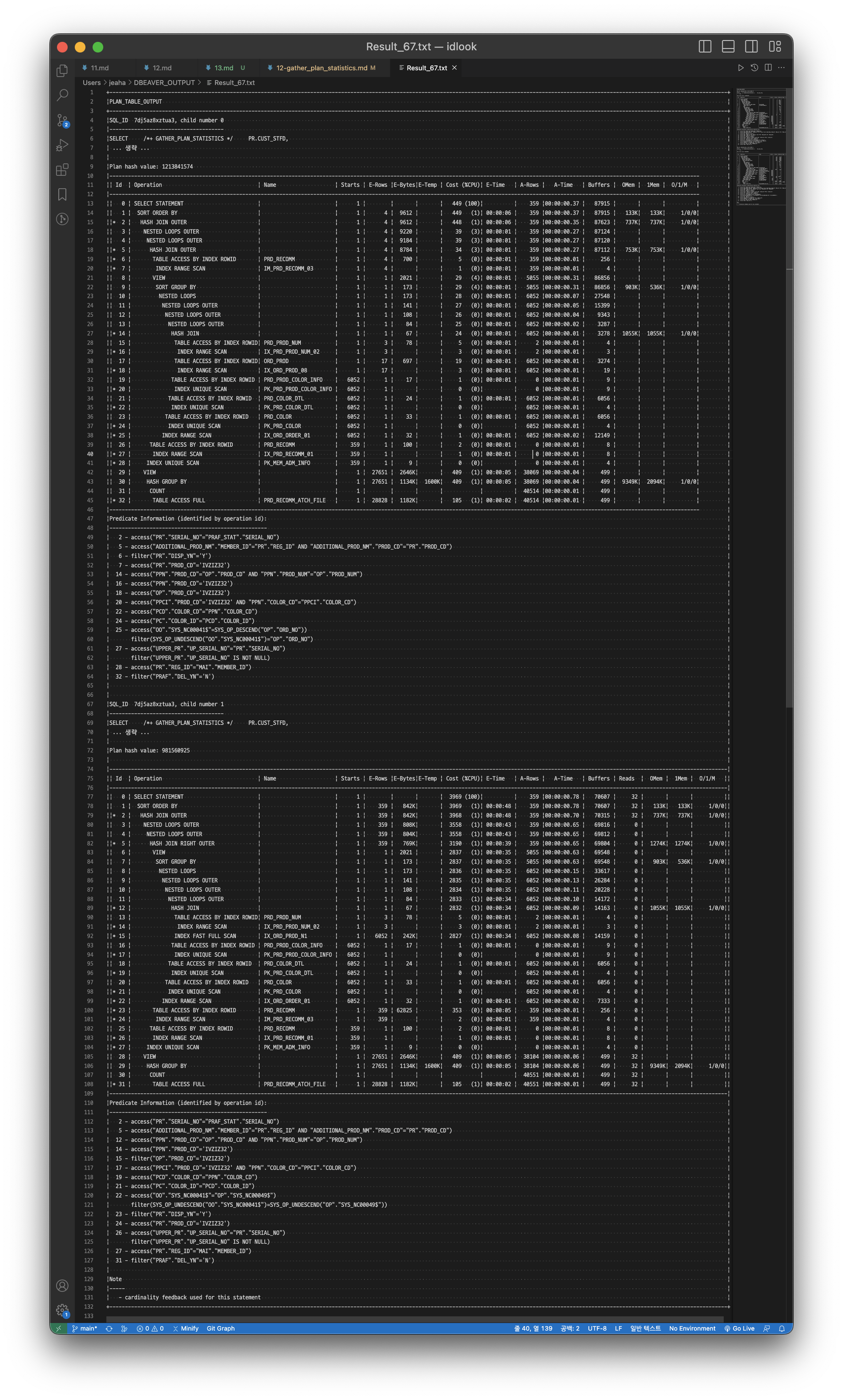
조회 결과 분석
Id, Operation, Name : 흔히 봐온 플랜 정보, 자원에 대한 접근 순서와 방법을 나타냄. 접근 순서를 변경할 수 있는 힌트 절은 ORDERED, LEADING이 있음. 또한 접근 방법을 변경할 수 있는 힌트절은 USE_NL, USE_HASH, USE_MERGE가 있음.
Starts : 오퍼레이션을 수행한 횟수를 의미한다. Starts * E-Rows 의 값이 A-Rows 값과 비슷하다면, 통계정보의 예측 Row 수와 실제 실행 결과에 따른 실제 Row 수가 유사하다고 함. 만약 값에 큰 차이가 있다면 통계정보가 실제의 정보를 제대로 반영하지 못했다고 봐야 한다고 함. 이로 인해 오라클의 Optimizer가 잘못된 실행 계획을 수립할 수도 있음을 염두에 둬야 함.
E-Rows (Estimated Rows) : 통계정보에 근거한 예측 Row 수를 의미. 통계정보를 갱신할수록 값이 매번 다를 수 있으며, 대부분의 DB 운영에서는 통계정보를 수시로 갱신하지 않으므로 해당 값에 큰 의미를 둘 필요는 없음. 하지만 E-Rows 값과 A-Rows 값이 현격하게 차이가 있다면 오라클이 잘못된 실행 계획을 세울 수도 있음을 인지해야 하며 통계정보 생성을 검토해 보아야 함.
A-Rows (Actual Rows) : 쿼리 실행 결과에 따른 실제 Row 수를 의미. A-Rows 에서 중요한 여러 정보를 추정 할 수 있음.
A-Time (Actual Elapsed Time) : 쿼리 실행 결과에 따른 실제 수행 시간을 의미. 실행 시점의 여러 상황이 늘 가변적이고 또한 메모리에 올라온 Block의 수에 따라서 수행 시간이 달라지므로 해당 값에 큰 의미를 두지 않는게 좋음.
Buffers (Logical Reads) : 논리적인 Get Block 수를 의미. 해당 값은 오라클 옵티마이저가 일한 총량을 의미하므로, 튜닝을 진행할 때 중요한 요소로 보임.
위의 헤더에서 튜닝 시 가장 중요하게 활용되는 부분은 Buffers, A-Rows. Buffers 값을 통해서 Get Block의 총량을 알 수 있고, A-Rows를 통해 플랜 단계별로 실제 Row 수를 알 수 있음.
DBMS_XPLAN.DISPLAY_CURSOR 조회 결과
SELECT * FROM TABLE (DBMS_XPLAN.DISPLAY_CURSOR('3YTNQSYC1PXJ8', NULL, 'ADVANCED ALLSTATS ALL -PROJECTION +ROWS +BYTES +PREDICATE'));
많은 필드를 불러 올수록 DB는 더 많은 로드를 부담하게 되기 때문에 꼭 필요한 열만 물러오도록 한다.
-- WORST
SELECT * FROM TABLE;
-- BETTER
SELECT COLUMN1, COLUMN2, COLUMN4, COLUMN8 FROM TABLE;
WHERE절에서 연산을 걸지 않는다.
연산이 들어가게 되면 TABLE FULL SCAN을 하면서 모든 값을 탐색, 계산 한 뒤 조건 충족 여부를 판단하기 때문에 좋지 않다.
-- WORST
SELECT COLUMN1, COLUMN4
FROM TABLE
WHERE FLOOR(COLUMN4) = 2;
-- BETTER
SELECT COLUMN1, COLUMN4
FROM TABLE
WHERE COLUMN4 BETWEEN 4 AND 5;
LIKE 조회시 와일드카드 % 는 가급적 뒤에만 붙이자
COLUMN6 LIKE %DF 는 TABLE FULL SCAN을 유발한다. COLUMN5 IN ('ASDF', 'ERDF'), COLUMN5 = 'ASDF' OR COLUMN5 = 'ERDF' 같은 형태가 낫다.
SELECT DISTINCT, UNION ALL 과 같이 중복을 제거하는 연산은 자제한다
중복을 제거하는 연산은 시간이 많이 걸린다. 불가피하게 사용해야 할 경우 EXISTS, GROUP BY를 활용하는게 낫다. DISTINCT는 원하는 컬럼에 대해서 중복을 제거하는 것이 아니라 SELECT 해온 모든 ROW에서 중복을 제거하므로 속도가 느려진다.
같은 내용의 조건이라면 GROUP BY 연산의 HAVING 보다는 WHERE 절을 사용하는 것이 좋다
쿼리 실행 순서에서 WHERE 절이 HAVING 절 보다 먼저 실행된다. 따라서 WHERE 절로 미리 데이터를 작게 만들면 GROUP BY 절에서 다뤄야 하는 데이터 크기가 작기 때문에 효율적인 연산이 가능하다.
VIEW VS MVIEW (MATERIALIZED VIEW)
뷰는 질의 할때마다 해당 쿼리를 재 실행하는 것과 같음. 속도가 느림. 다만 데이터는 LIVE 함. MVIEW는 세팅을 어떻게 하느냐에 따라 질의 할 쿼리를 재사용하여 가져옴. 스냅샷 처럼 이전에 만들어 놓은 엠뷰 테이블에서 데이터를 가져옴. 비용이 많이 들어가고 데이터가 고정적인 경우 엠뷰를 만들어서 사용하는게 좋음. 인덱스도 생성 가능. 리프레시 타임이 많이 드는 경우 데이터가 LIVE하지 않은 문제가 있음.
CHAR VS VARCHAR
4byte 이하는 CHAR, 그 이상은 VARCHAR가 나음.
CHAR : 고정 길이 문자열
VARCHAR : 가변 길이 문자열
BLOB VS TEXT
많은 양의 데이터 저장, 디폴트 값 지정 안됨, 문자열 뒷부분 공백 제거 안되는 공통점이 있음. 차이점으로 BLOB은 대소문자를 구분, TEXT는 구분 안함.
PRIMARY KEY, UNIQUE KEY
PK와 Unique Key는 자동으로 인덱스가 생성됨.
쿼리 실행 순서
SUB-QUERY -> MAIN-QUERY
INNER JOIN시 테이블 배치 순서
3개 이상의 테이블을 INNER JOIN을 할 때는 크기가 가장 큰 테이블을 FROM 절에 배치하고 INNER JOIN 절에 남은 테이블을 작은 순서대로 배치하는 것이 좋다. 테이블 한두개차이는 상관 없지만 많은 테이블을 JOIN 할 경우 JOIN의 경우의 수가 생기고 OPTIMIZER가 PLANNING을 하면서 비용이 증가된다.
실행 계획 type이 index라면 한 번 더 살펴보기
EXPLAIN으로 실행 계획을 확인 했을 때 type이 index인 부분이 있다. where 절 조건문에서 사용하는 테이블의 컬럼에 인덱스가 제대로 걸려있지 않기 때문에 TABLE FULL SCAN을 한다. 해당 테이블에 index를 걸고 다시 실행 계획을 INDEX RANGE SCAN으로 변경되었고 실제 실행 속도가 1/4로 줄었다. 아래는 type의 종류로 성능이 낮은 것 부터 높은 순으로 정렬했다.
ALL : 테이블을 처음부터 끝까지 탐색하여 데이터를 찾음 (TABLE FULL SCAN)
INDEX : 인덱스를 처음부터 끝까지 탐색하여 데이터를 찾는 방식 (INDEX FULL SCAN)
RANGE : 특정 범위 내에서 인덱스를 사용하여 원하는 데이터를 추출, 데이터가 방대하지 않다면 준수함. (INDEX RANGE SCAN)
REF : 조인 할 때 Primary Key 혹은 Unique Key 가 아닌 Key로 매칭 한 경우
이론 적인 것은 잘 정리된 글이 많기 때문에 생략. java로 int 형 stack과 Object형 stack을 구현한 코드.
int 형을 저장하는 스택
public class IntStack {
// 스택용 배열
private int[] stk;
// 스택 용량
private int capacity;
// 스택 포인터
private int ptr;
// 실행 시 예외 : 스택이 비어있는 경우
public class EmptyIntStackException extends RuntimeException {
public EmptyIntStackException(){}
}
// 실행 시 예외 : 스택이 가득 찬 경우
public class OverflowIntStackException extends RuntimeException {
public OverflowIntStackException(){}
}
// 생성자
public IntStack(int maxLen) {
ptr = 0;
capacity = maxLen;
try {
// 스택 본채용 배열 생성
stk = new int[capacity];
} catch (OutOfMemoryError e) {
// 생성할 수 없음
capacity = 0;
}
}
// 스택에 X를 푸시
public int push(int x) throws OverflowIntStackException {
if (ptr >= capacity)
// 스택이 가득 찬 경우
throw new OverflowIntStackException();
return stk[ptr++] = x;
}
// 스택에서 데이터를 팝 (꼭대기에 있는 데이터를 꺼냄)
public int pop() throws EmptyIntStackException {
if (ptr <= 0)
// 스택이 비어 있음
throw new EmptyIntStackException();
return stk[--ptr];
}
// 스택에서 데이트를 피크 (꼭대기에 있는 데이터 조회)
public int peek() throws EmptyIntStackException {
if (ptr <= 0)
// 스택이 비어 있음
throw new EmptyIntStackException();
return stk[ptr - 1];
}
// 스택을 비움
public void clear() {
// 모든 작업이 ptr 값으로 이루어 지므로 배열의 요소를 변경할 필요가 없음.
ptr = 0;
}
// 스택에서 X 찾아 인덱스 반환, 없다면 -1 반환
public int indexOf(int x) {
// 뒤(꼭대기)에서 부터 선형 탐색
for (int i = ptr - 1; i >= 0; i--) {
if (stk[i] == x)
// 검색 성공
return i;
}
// 검색 실패
return -1;
}
// 스택의 용량 반환
public int getCapacity() {
return this.capacity;
}
// 스택에 쌓여있는 데이터 개수 반환
public int size() {
return ptr;
}
// 스택이 비어있는지 확인
public boolean isEmpty() {
return ptr <= 0;
}
// 스택이 가득 찼는지 확인
public boolean isFull() {
return ptr >= capacity;
}
public void dump() {
if (ptr <= 0)
System.out.println("EMPTY STACK");
else {
for (int i = 0; i < ptr; i++)
System.out.print(stk[i] + " ");
System.out.println("");
}
}
}
Object 형을 저장하는 스택
// 임의의 객체형을 쌓을 수 있는 테네릭 스택 클래서 Stack<E> 작성
public class GenericStack<E> {
// 스택용 배열
private E[] stk;
// 스택 용량
private int capacity;
// 스택 포인터
private int ptr;
// 실행 시 예외 : 스택이 비어있는 경우
public static class EmptyGStackException extends RuntimeException {
public EmptyGStackException(){}
}
// 실행 시 예외 : 스택이 가득 찬 경우
public static class OverflowGStackException extends RuntimeException {
public OverflowGStackException(){}
}
// 생성자
public GenericStack(int maxLen) {
ptr = 0;
capacity = maxLen;
try {
// 스택 본채용 배열 생성
stk = (E[])new Object[capacity];
} catch (OutOfMemoryError e) {
// 생성할 수 없음
capacity = 0;
}
}
// 스택에 X를 푸시
public E push(E x) throws OverflowGStackException {
if (ptr >= capacity)
// 스택이 가득 찬 경우
throw new OverflowGStackException();
return stk[ptr++] = x;
}
// 스택에서 데이터를 팝 (꼭대기에 있는 데이터를 꺼냄)
public E pop() throws EmptyGStackException {
if (ptr <= 0)
// 스택이 비어 있음
throw new EmptyGStackException();
return stk[--ptr];
}
// 스택에서 데이트를 피크 (꼭대기에 있는 데이터 조회)
public E peek() throws EmptyGStackException {
if (ptr <= 0)
// 스택이 비어 있음
throw new EmptyGStackException();
return stk[ptr - 1];
}
// 스택을 비움
public void clear() {
// 모든 작업이 ptr 값으로 이루어 지므로 배열의 요소를 변경할 필요가 없음.
ptr = 0;
}
// 스택에서 X 찾아 인덱스 반환, 없다면 -1 반환
public int indexOf(Object x) {
// 뒤(꼭대기)에서 부터 선형 탐색
for (int i = ptr - 1; i >= 0; i--) {
if (stk[i].equals(x))
// 검색 성공
return i;
}
// 검색 실패
return -1;
}
// 스택의 용량 반환
public int getCapacity() {
return this.capacity;
}
// 스택에 쌓여있는 데이터 개수 반환
public int size() {
return ptr;
}
// 스택이 비어있는지 확인
public boolean isEmpty() {
return ptr <= 0;
}
// 스택이 가득 찼는지 확인
public boolean isFull() {
return ptr >= capacity;
}
public void dump() {
if (ptr <= 0)
System.out.println("EMPTY STACK");
else {
for (int i = 0; i < ptr; i++)
System.out.print(stk[i] + " ");
System.out.println("");
}
}
}
"나쁜 코드는 기술 부채를 만들어 수정을 더 어렵게 하며 결국 조직의 생산성을 저하시킨다."
이 책을 추천 받은 것은 개발 쪽으로 전향한 지 얼마 안되서였던 것 같다. 인터넷에서 추천받았었는지, 아니면 국비지원 학원이 끝나갈 무렵이었는지 정확히는 기억나지 않는다. 그리고 최근에 내가 잘 따르던 선배의 강력한 추천이 한번 더 있었다. 어쨌든 토비의 스프링과 함께 한 번은 봐야지 하던 책이었고, 이번에 드디어 완독을 했다. 아니 1독을 했다고 표현해야겠다.
읽코 좋코가 이 책 보다 조금 더 쉽게 읽힌달까. 나중에 후배들을 맞이하고, 혹은 팀을 이끌어갈 때쯤 2독 3독을 해야 할 책이라고 생각된다. 충분히 많은 도움이 된 좋은 책이지만, 내 경험이 짧아 이해하기 어려운 부분도 많고 확실히 내 수준보다는 더 높았다. 아마도 TDD 라던지, 객체지향 패러다임을 잘 따르는 코드를 본 적이 없어서일까? 아무튼 프로세스를 만들 때 가져야 할 마음 가짐에 대해서 많이 생각하게 되었다. 의미를 가진 코드, 코드의 문맥, 추상화 수준과 왜 그렇게 해야 하는지의 이유도 잘 설명되었다. 코드가 마치 잘 쓰여진 소설처럼 읽힐 수 있도록 작성한다는 마음가짐으로 코딩을 하게 되었다. 단순하게 동작이 목적이 아닌 쉽게 읽힐 수 있도록 고민을 하다 보니 더 직관적이고 객체지향 구조로 코드를 짤 수 있었던 것 같다.
선배가 이 책을 추천할 때, 레거시 코드에 대해 정말 화를 내고 열변을 토했던 것으로 기억한다. 그리고 이 책을 읽으면서 그가 이 책을 추천하면서 왜 그렇게 화를 냈는지 납득했다. 저자는 나쁜 코드가 나쁜 이유에 대해서 여러 예를 들고 그중 기억에 남는 것은 위의 두 문장이다.
나 역시도 나쁜 코드를 혐오한다. 레거시 코드를 유지보수하면서 소스코드의 히스토리를 보면 왜 이런 코드가 생겼는지 납득할 수 있지만, 그렇다면 처음부터 더 좋은 구조로 작성될 순 없었는가 하는 의문이 들곤 한다. 솔직하게 말해서 나쁜 코드를 보면 화도 나고 작성자를 기둥에 묶어두고 싶다는 생각도 든다. 나를 포함한 많은 개발자들이 이 책을 읽고 객체지향 패러다임과 클린코드 원칙들을 따르는, 개발을 잘하는, 후배들에게 좋은 코드를 남기는 시니어가 될 수 있도록 갈고닦기를... 🙏🏻
모든 전공 서적들이 빠르게 읽히지 않는데, 다른 전공서적에 비해 쉽게 읽히는 책이며 많은 공감을 하게 되었다. 제목과 내용은 동일하며 주제를 반복 강조하고 있다. 이를 위해 변수명, 함수명, 코드 컨벤션 그리고 리팩토링까지 설명하고 있다. 코드는 이해하기 쉬워야 한다, 다시 말해 코드를 읽는데 드는 비용을 줄여야 한다는 말이다. 코드 파악하는데 드는 비용이 작다는 말은 설계가 명확하고 간결하다는 의미를 내포한다.
이 책을 읽고 실제 코드로 적용할 생각을 하면 머리가 아프지만 읽는 중간 중간 이전에 보았던 코드들이 떠올랐다. 이전에 작성 했던 '성능과 가독성을 높이는 분기처리 방법'을 쓸 때 보다 시야가 더 넓어졌다. "왜?"에 대한 부분이 조금 모호했었는데, 그 부분을 채워주는 내용이였다. 그리고 내가 봐온 레거시 프로젝트들의 코드를 작성했던 개발자들에게 이 책을 던져주고 싶었다.
코드는 이해하기 쉬워야 한다 인상 깊었던 내용은 6개월 뒤의 나 자신 또한 쉽게 이해되도록 코드를 작성하라는 내용이였다. 나 역시도 나름의 설명과 주석을 잘 붙여서 만들었다고 생각했지만 1년 뒤 해당 코드를 개선 하면서 다시 분석해 보는 헛수고를 했던 경험이 있었다. 짧은 코드가 더 좋은 코드가 아닌 읽는 순간 바로 이해되는 코드가 좋은 코드라는 뜻이다.
이름에 정보 담기
구체적인 단어 사용하기
이름 길이(짧은 범위에 잠깐 쓰이면 짧은 변수명, 사용 범위가 넓다면 긴 변수명, 약어 사용 지양하기 등)
포맷팅으로 의미 전달하기(상수는 대문자, 클래스명은 카멜케이스 등)가 있었다.
오해할 수 없는 이름들
경계를 포함하는 범위 : first, last
경계를 포함/배제하는 범위 : begin, end 사용
불린 : is, has, can, should 사용
get 남발하지 않기
여러 개의 이름을 후보로 놓고 고민하기
'다른 사람들이 다른 의미로 해석할 여지가 있는가?'가 핵심이였다. 한 번쯤 더 생각해 보면 더 좋은 변수명을 만들 수 있다.
미학
문서 작업을 하더라도 한눈에 보기 쉽게 쓰인 글이 잘 읽히듯 코드도 마찬가지다.
좌우로 길게 늘어진 코드는 줄 바꿈을 하고 다른 코드들도 똑같이 맞추기
헬퍼 메소드를 이용하여 지저분한 코드 깔끔하게 하기
코드의 위아래 열을 맞추어 읽기 쉽게 하기
코드의 순서를 '가장 중요한 것'에서 '가장 덜 중요한 것' 까지 순서대로 나열하기
코드를 문단으로 만들기 (핸들러, DB 사용 등 문맥이 바뀌면 한 행을 띄우는 등 글을 쓸때 문단을 나누는 것과 동일)
개인의 코드 스타일 VS 전체 코드의 일관성 = 일관성이 올바른 스타일보다 더 중요
주석에 담아야 하는 대상
불필요한 설명 배제
나쁜 이름에 대한 변명이 아니라 좋은 이름으로 바꿀 것
작업중 생각한 통찰 등을 주석에 기록
ex: 하위클래스로 정리해야 할 것 같다
상수의 의미를 설명할 것
다른 개발자가 실수할 수 있는 부분을 예상해서 주석을 달라
ex : 1분 후 타임아웃 된다
2, 3중 반복/조건문이 달린 함수는 무엇을 위한 것인지 요약 주석을 단다
주석을 다는 것에 대한 두려움을 버려라
명확하고 간결한 주석 달기
간단한 입출력 예시 사용
코드의 수행 동작이 아니라 코드의 의도를 적어라
파라미터에도 주석을 넣어라
축약된 단어를 사용하라
ex : ~에서 불필요한 빈칸을 제거한다 -> 공백 제거
읽기 쉽게 흐름 제어 만들기
조건문에서 유동적인 값은 왼쪽, 상대적으로 고정적인 값은 오른쪽에 쓰라
if/else 간단한 것을 먼저 처리하라
삼항 연산자의 사용은 간단하게 쓸 상황이 아니라면 피하라
중첩을 피하기 위해 함수를 중간에서 반환하라
2중 if 문은 나누어서 중간에 반환하라
거대한 표현 잘게 쪼개기
요약 변수 사용, 조건식의 반복되는 중요 비교 값을 상수로 만들기
드모르간의 법칙 사용
short circuit 사용을 오용하지 말 것
영리하게 작성된 코드가 혼란을 초래한다
복잡한 논리를 간단하게 표현하기
거대한 구문은 문맥에 따라 나누기
변수와 가독성
불필요한 임시 변수, 중간 결과 저장 변수, 흐름 변수(boolean) 제거하기
변수의 범위 좁히기
클래스를 작은 단위로 나누기
전역변수 사용 피하기
변수에 다른 값을 여러번 할당하는 것 피하기
상관 없는 하위 문제 추출하기
비즈니스 로직과 관계 없는 문자열 빈칸 제거, url 형식, 주소 형식등을 다루는 메소드는 분리하기
스프링 사용자로서 항상 읽어야봐야 한다라는 소리에 두권을 샀지만, 엄청 어렵다는 소문에 읽을 엄두를 못 내던 책이다. 한 권에 800 페이지가 넘는 굉장한 분량에 두번의 정독 시도를 헛탕쳤었다. [유튜브] "개발바닥" 채널에서 저자 이일민님의 인터뷰와, 그 분이 이제는 스프링 부트 인강을 내시면서 이 책을 다시 시도하였고. 이번에는 1독을 끝냈다. 이제 4년차에 들어서면서 읽어보니 '어느 정도 개발을 했고, 좋은 구조와 효율을 고민해본 사람이 봐야 깊은 뜻을 더 잘 이해할 수 있겠구나' 라고 느꼈다.
이 책은 객체지향적 설계, 리팩토링, 테스트주도개발의 중요성에 대해 꾸준히 강조하고 있다. 단순하게 스프링 프레임워크의 기능 / 개념에 대한 설명도 깊게 나와있지만, 이 책의 요점은 스프링이 왜 이렇게 발전했고, 어떤 패러다임을 녹여서 만든건지 엿볼 수 있도록 도와주는 책이다. 따라서 개발 철학에 더 중점을 두고 읽어야 하는 책이라고 생각 된다.
마틴 파울러와 켄트 백이 강조하던 내용이 녹아 있으며, 아래와 같은 조언을 책 전반에 걸쳐 꾸준히 강조하고 있다.
'고정된 작업 흐름을 갖고 있으면서 여기저기서 자주 반복되는 코드가 있다면, 중복되는 코드를 분리할 방법을 생각해보는 습관을 기르자.'
'비슷한 기능이 새로 필요할 때마다 앞에서 만든 코드를 복사해서 사용할 것인가? 물론 아니어야 한다. 한두 번까지는 어떻게 넘어간다고 해도, 세번 이상 반복된다면 본격적으로 코드를 개선할 시점이라고 생각해야 한다.'
인상 깊었던 문장
인상 깊었던 문장들은 다음과 같다. 다 읽어보면 떠오르는 것이 있다. 그렇다, 대부분의 레거시 프로젝트의 소스들은 아래에서 하지 말라는 대로 개발되어 있다.
계층형 아키텍쳐
관심, 책임, 성격, 변하는 이유와 방식이 서로 다른 것들을 분리함으로써 분리된 각 요소의 응집도는 높여주고 서로 결합도를 낮춰줬을 때의 장점과 유익이 무엇인지 살펴봤다. 성격이 다른 모듈이 강하게 결합되어 한데 모여 있으면 한 가지 이유로 변경이 일어날 때 그와 상관이 없는 요소도 함께 영향을 받게 된다. 따라서 불필요한 부분까지 변경이 일어나고 그로 인해 작업은 더뎌지고 오류가 발생할 가능성이 높아진다. 어느 부분을 수정해야할지를 파악하기도 쉽지 않다.
따라서 인터페이스와 같은 유연한 경계를 만들어 두고 분리하거나 모아주는 작업이 필요하다.
또, 흔히 저지르는 실수 중의 하나는 프레젠테이션 계층의 오브젝트를 그대로 서비스 계층으로 전달하는 것이다.
서블릿의 HttpServletRequest나 HttpServletResponse, HttpSession 같은 타입을 서비스 계층 인터페이스 메소드의 파라미터 타입으로 사용하면 안 된다.
계층의 경계를 넘어갈 때는 반드시 특정 계층에 종속되니 않는 오브젝트 형태로 변환해줘야 한다.
스프링을 사용하면 이런 데이터 중심의 코드를 만들 수 있을 뿐만 아니라, 실제로 매우 흔하게 발견된다.
데이터와 업무 트랜잭션 중심의 개발에 익숙한 사람들이 많고 이런 아키텍쳐를 의도적으로 선호하는 개발자도 많기 때문이다.
개발자들끼리 서로 간선없이 자신에게 할당된 기능을 독립적으로 만드는 데도 편하다.
최소한의 공통 모듈 정도만 제공되는 것을 사용하고, 그 외의 기능은 단위 업무 또는 웹 화면 단위로 만들어 진다.
하지만 이런 개발 방식은 변화에 매우 취약하다.
객체지향의 장점이 별로 활용되지 못하는데다 각 계층의 코드가 긴밀하게 연결되어 있기 때문이다.
중복을 제거하기도 쉽지 않다.
업무 트랜잭션에 따라 필드 하나가 달라도 거의 비슷한 DAO 메소드를 새로 만들기도 한다.
또한 로직을 DB와 SQL에 많이 담으면 담을수록 점점 확장성이 떨어진다.
DB는 확장에 한계가 있을 뿐 아니라 확장한다 하더라도 매우 큰 비용이 든다.
잘 작성된 복잡한 SQL 하나가 수백 라인의 자바 코드가 필요한 비지니스 로직을 한번에 처리할 수도 있다.
하지만 과연 바람직한 것일까?
이런 복잡한 sql을 누구나 쉽게 이해하고 필요에 따라 유연하게 변경할 수 있을까?
또, 복잡한 sql을 처리하기 위해 제한된 자원인 DB에 큰 부담을 주는 게 과연 바람직한 일인지 생각해볼 필요가 있다.
데이터 중심 아키텍쳐의 특징은 계층 사이의 결합도가 높은 편이고 응집도는 떨어진다는 접이다.
화면을 중심으로 하는 업무 트랜잭션 단위로 코드가 모이기 때문에 처음엔 개발하기 편하지만 중복이 많아지기 쉽고 장기적으로 코드를 관리하고 발전시키기 힘들다는 단점이 있다.
스프링은 그 개발철학과 목표를 분명히 이해하고 사용해야 한다.
자바의 근본인 OOP 원리에 충실하게 개발할 수 있으며,
환경이나 규약에 의존적이지 않은 POJO를 이용한 애플리케이션 개발은
엔터프라이즈 시스템 개발의 복잡함이 주는 많은 문제를 해결할 수 있다.
POJO 방식의 개발을 돕기 위해 스프링은 IoC/DI, AOP, PSA와 같은 기능 기술을 프레임워크와 컨테이너라는 방식을 통해 제공한다.
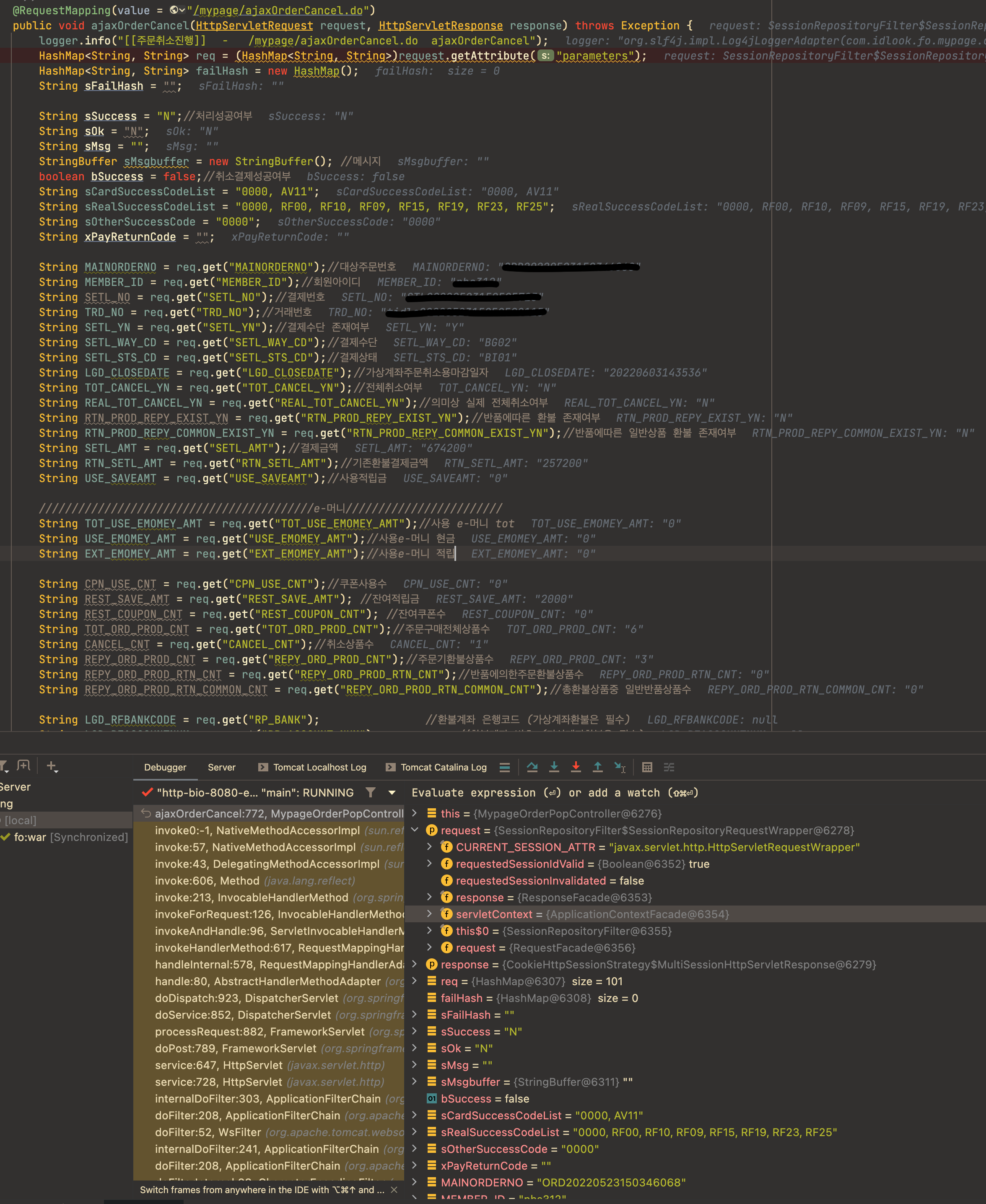
디버그 모드로 애플리케이션을 구동시키면 아래 스크린샷과 같이 변수, 객체 등의 값을 알 수 있다. log를 찍거나 system print 등을 사용하지 앖아도 실시간으로 값을 알 수 있고 브레이크 포인트를 사용해서 트래킹 하는데 수월하니 앞으로는 IDE의 디버그 모드를 적극 활용하자. intellij 나 eclipse 모두 지원한다.
IntelliJ의 디버그 모드
2. Comment 제거
아래 기준을 참고해서 과감하게 기존 코멘트를 제거한다.
위 디버그 모드 활용과 더불어 단순 값 확인용 코멘트는 제거한다.
의미없는 ‘//////////////’ 와 같은 구분선 종류의 코멘트는 제거한다.
Github을 통해 트래킹, 복원이 쉽기 때문에 불필요한 주석은 과감하게 제거한다.
3. 선언, 초기화, 디폴트에 신경쓰자
코드 품질은 디테일에서 나온다. 그리고 디테일은 기본기 없이 챙기기 힘들다. 아래 스크린샷을 보자.
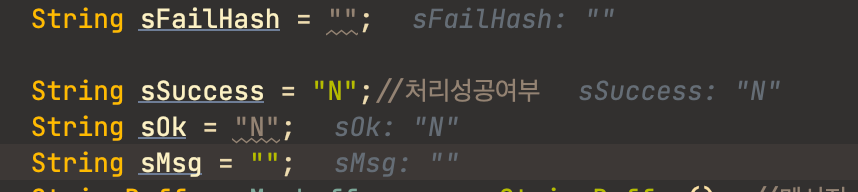
선언부 이후에 로직 중에 항상 해당 변수에 값을 할당한다면 굳이 선언하면서 초기화 할 필요가 없다.
의미없는 값으로 대충 초기화 하는 습관은 멀리하자. 초기화 하는 값은 일반적으로 디폴트 값이어야 하고 이 디폴트 값이 뭔지 정확히 알고서 초기화 해야한다.
4. 가독성을 높이자
// Before
// 결제상점아이디에 따른 분기
if (TRD_NO.indexOf(oldIdPart) >= 0) {
sMallID = oldMid;
}
// After
if (TRD_NO.contains(oldIdPart)) {
sMallID = oldMid;
}
위 코드는 파라미터로 넘긴 string의 존재 여부를 검사한 뒤 그에 따른 처리를 하기위한 것으로 보인다. 그래서 자바의 String에 있는indexOf() 메소드를 사용해 >= 0 조건으로 판별한다. 이 코드는 기능상 아무 이상 없이 작성자의 의도대로 잘 작동한다.
앞서 이야기한 것처럼 이런 코드에서 보이는 디테일을 잡으면 가독성과 품질이 상승한다.
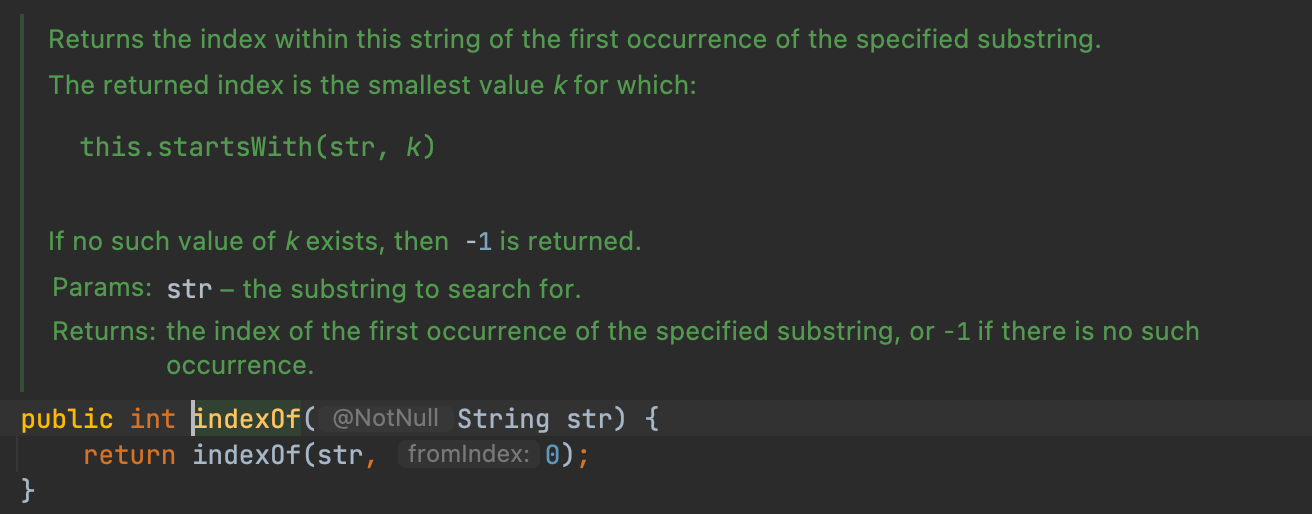
indexOf 와 contains
자바에는 각 객체를 위한 유틸 메소드들이 많다. 그 중 contains라는 메소드로 indexOf를 대체할 수 있다. contains의 내용은 아래 스크린샷처럼 indexOf를 래핑한 메소드다. 따라서 성능이나 기능에선 차이가 없다고 봐도 된다.
JDK 1.5에 생긴 containsindexOf
그럼 왜 indexOf를 contains로 대체하려고 하는거고 언제 써야 할까?
indexOf와 contains는 용도가 다르다.
indexOf는 스트링이 시작되는 index를 int값으로 반환하고 contains는 스트링의 포함 여부를 판단해 boolean으로 반환한다. 따라서 특정 비즈니스 로직 혹은 알고리즘을 구현하기 위한 경우가 아니면 일반적인 경우에 contains의 목적으로 더 많이 쓰게 된다.
Readability
물론 indexOf를 보고 >= 0 조건을 보면 뭘 하려는지 알 수 있다. 하지만 contains라는 단어가 그 모든걸 포함하기 때문에 훨씬 더 직관적이다. contains쓰면 indexOf라는 메소드는 잘 썼는지, 뒤에 >=0 인지 > 0 인지 > -1 인지 잘못쓰진 않았는지 이런 생각 할 필요도 없다. 가독성을 정의할 때 그저 문자가 잘 읽히는 정도를 넘어서 (특히 메소드는) 이름에 맞는 목적과 기능을 신뢰할 수 있어서 불필요한 생각도 줄여주는 수준까지 갈 수 있도록 신경써야 한다.
5. Naming - 변수명은 중요하다
현재 레거시 코드의 문제점
프론트 HTML tag'name을 그대로 백엔드 로직에 사용함
마크업과 프론트 사정에 따른 hChk, pChk 와 같은 변수명 백엔드에서 실제 용도를 구분하기 어려움
변수명과 주석이 일치하지 않거나 주석의 뜻을 담아내기에 부족한 변수명이 많음
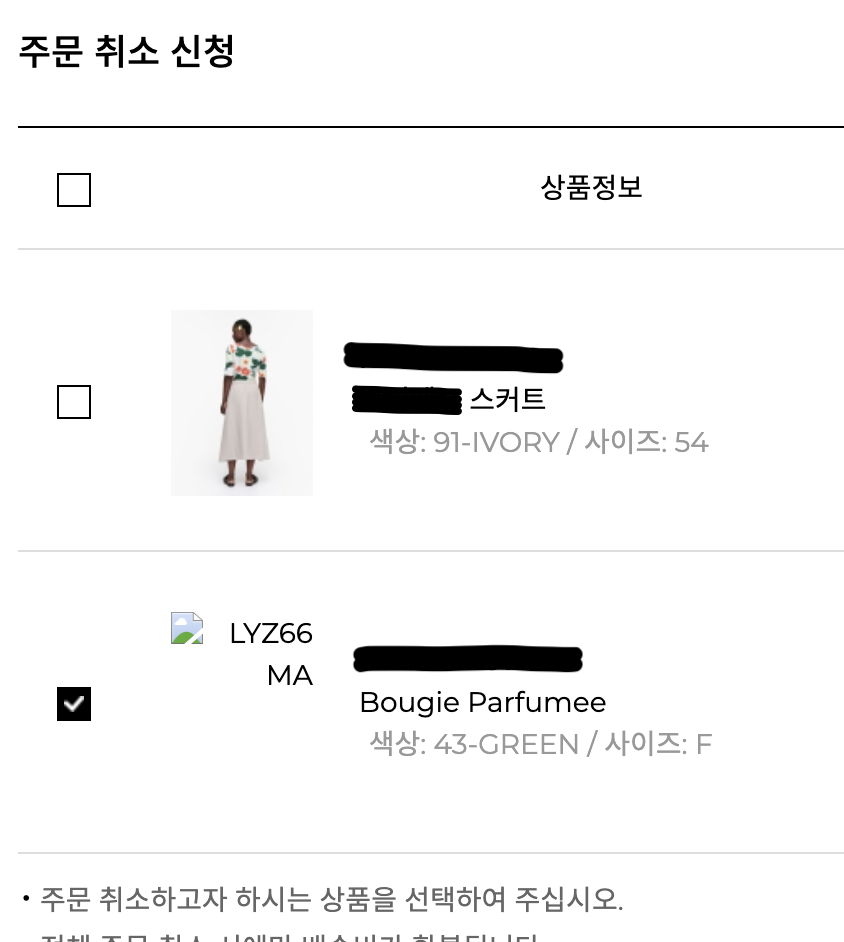
실제 주문취소에서 볼 수 있는 케이스는 아래와 같다.
// bad case
String[] hChk = request.getParameterValues("hChk");//선택여부
// good case
String[] cancelSelectYn = request.getParameterValues("hChk"); // 취소선택여부
위 변수가 가리키고 있는 건 주문 취소 시 상품 별 체크박스 값이다.(아래 스크린샷) 따라서 hChk 라는 이름을 그대로 백엔드 로직에도 차용한다면 코드 전체를 트래킹 해야 하는 수고가 더해진다. 그래서 이름을 취소선택여부, 취소신청여부 등으로 하고 변수명도 이에 맞춰 수정하는 것이 좋다.
주문 취소 상품 선택화면
하지만 실제로 레거시 시스템은 볼륨도 크고 복잡한 상호관계를 이미 가지고 있는 상태기 때문에 변수명만 바꾸기에 위험하다. 래거시 프로젝트 소스코드도 마찬가지이며 따라서 변수명을 바꾸려 할 땐 아래 항목을 점검해서 진행한다.
JSP와 JAVA에서 동일하게 사용하고 있는 변수가 response나 query에서 반드시 동일하도록 짜여 있는지
주석과 변수명이 다르다면 둘 중 어느 것이 맞는지, 둘 다 틀린지
변수명을 바꿨을 때 영향 범위가 백엔드 비즈니스 로직에만 해당되는지
6. 조회와 요청, 트랜젝션
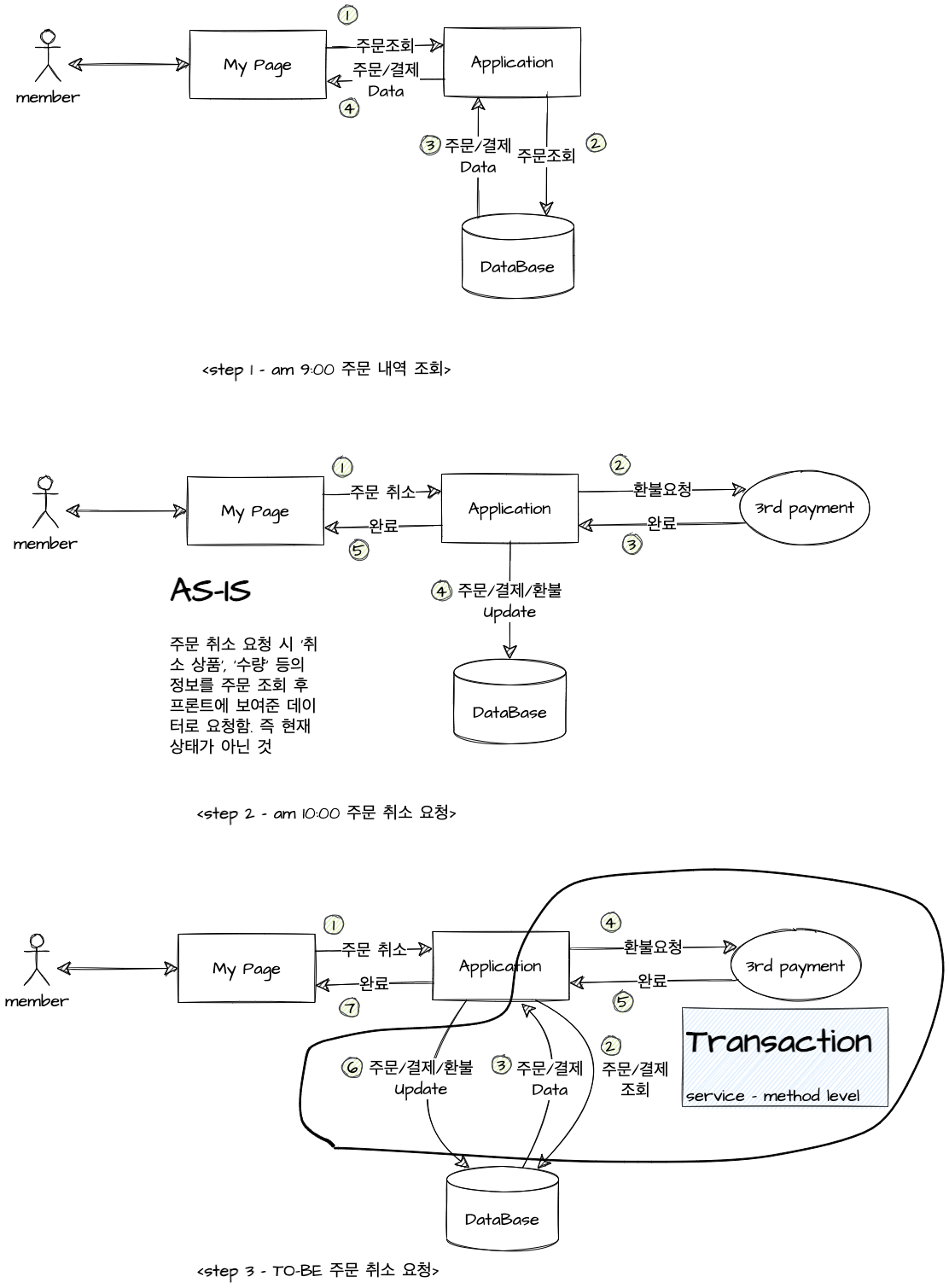
사용자의 화면에 보이는 내용은 화면을 그리는 시점에 유효한 정보이다(화면을 실시간으로 갱신하지 않는한)
현재 프로세스는 <step 2> 와 같고 주문 취소 요청 시 JSP에 뿌려진 주문/결제 값으로 환불요청을 시작한다
때문에 주문 조회 시점과 환불 요청 시점 차이가 있을 때 주문 상태 차이가 발생할 수 있고 중복 발생 가능성 또한 있는 구조다.
개선 프로세스는 <step 3> 와 같이 사용자 요청을 받고 현재 주문과 환불 진행상태 등을 DB에서 조회하는 ② 부터 완료된 주문/결제/환불 정보를 DB에 업데이트하는 ⑥ 까지를 하나의 트랜잭션으로 묶는다.
대부분의 레거시 프로젝트 코드에는 화면에서 가져온 값들로 무언가 처리하는 로직이 많은데 전반적인 수정이 필요하다.
7. 3-tier Architecture
아래 쿼리를 먼저 보자.
// 이런 패턴
, X.BANK_CD <!--은행코드-->
, CASE WHEN X.BANK_CD IS NOT NULL
THEN DECODE(X.BANK_CD, '02', '산업', '03', '기업', '05', '외환', '06', '국민', '07', '수협', '11', '농협', '20', '우리', '23', 'SC제일', '27', '한국씨티', '31', '대구'
, '32', '부산', '34', '광주', '35', '제주', '37', '전북', '39', '경남', '45', '새마을금고', '48', '신협', '71', '우체국', '81', '하나', '88'
, '신한(계좌이체)', '26', '신한(가상계좌)','S0', '동양증권', 'S1', '미래에셋', 'S2', '신한금융투자', 'S3', '삼성증권', 'S6', '한국투자증권' , 'SG', '한화증권')
ELSE '-'
END BANK_NM <!--은행명-->
// 비슷한 패턴
, X.MEMO <!--메모(가상)-->
, NVL(X.MEMO, 'X') SHW_MEMO <!--화면용메모(가상)-->
// 비슷한 패턴
, X.RECP_PSN_TELNO <!--수령인전화번호-->
, CASE WHEN LENGTH(REPLACE(NVL(X.RECP_PSN_TELNO, 'X'), '-', '')) <![CDATA[ < ]]> 9
THEN 'X'
ELSE X.RECP_PSN_TELNO
END SHW_RECP_PSN_TELNO <!--수령인전화번호-->
안좋은 케이스로 보이는 건..
쿼리 안에서 데이터 가공을 한다는 것이다. 게다가 화면에 보여줄 목적인 것들이 꽤 있다.
코드 관리나 관련 메소드가 애플리케이션에 있는게 아니라 쿼리에 들어가 있다.
대부분의 레거시 프로젝트들은 JSP, Spring, Oracle 기반이지만 잘 구분된 계층 구조를 이루고 있지 않다. 해당 계층에서 해야 할 일들이 다른 계층으로 번져간다면 결국 문제가 생길때마다 화면~데이터 모든 영역의 코드를 살펴봐야만 어느 부분이 문제인지 찾아낼 수 있다. 그래서 앞으로 신규 개발하는 화면, 기능은 이러한 강한 결합을 피하고 우리 시스템과 기술이 지향하는 3티어 계층에 맞춰 프로그래밍을 하도록 한다. 추후 가이던스를 마련하고 공유하겠지만 먼저 간단하게 요약하면 아래와 같다.